![]()
Lesson 2 Data Engineering for ML on AWS
Watch Lesson 2: Data Engineering for ML on AWS Video
Pragmatic AI Labs
![]()
This notebook was produced by Pragmatic AI Labs. You can continue learning about these topics by:
- Buying a copy of Pragmatic AI: An Introduction to Cloud-Based Machine Learning from Informit.
- Buying a copy of Pragmatic AI: An Introduction to Cloud-Based Machine Learning from Amazon
- Reading an online copy of Pragmatic AI:Pragmatic AI: An Introduction to Cloud-Based Machine Learning
- Watching video Essential Machine Learning and AI with Python and Jupyter Notebook-Video-SafariOnline on Safari Books Online.
- Watching video AWS Certified Machine Learning-Speciality
- Purchasing video Essential Machine Learning and AI with Python and Jupyter Notebook- Purchase Video
- Viewing more content at noahgift.com
Load AWS API Keys
Put keys in local or remote GDrive:
cp ~/.aws/credentials /Users/myname/Google\ Drive/awsml/
Mount GDrive
from google.colab import drive
drive.mount('/content/gdrive', force_remount=True)
import os;os.listdir("/content/gdrive/My Drive/awsml")
Install Boto
!pip -q install boto3
Create API Config
!mkdir -p ~/.aws &&\
cp /content/gdrive/My\ Drive/awsml/credentials ~/.aws/credentials
Test Comprehend API Call
import boto3
comprehend = boto3.client(service_name='comprehend', region_name="us-east-1")
text = "There is smoke in San Francisco"
comprehend.detect_sentiment(Text=text, LanguageCode='en')
2.1 Data Ingestion Concepts
Data Lakes
Central Repository for all data at any scale

AWS Lake Formation
- New Service Announced at Reinvent 2018
- Build a secure lake in days…not months
- Enforce security policies
- Gain and manage insights

Kinesis (STREAMING)
Solves Three Key Problems
- Time-series Analytics
- Real-time Dashboards
- Real-time Metrics
Kinesis Analytics Workflow

Kinesis Real-Time Log Analytics Example

Kinesis Ad Tech Pipeline

Kinesis IoT

[Demo] Kinesis
AWS Batch (BATCH)
Example could be Financial Service Trade Analysis

Using AWS Batch for ML Jobs
https://aws.amazon.com/batch/

Example submissions tool
@cli.group()
def run():
"""Run AWS Batch"""
@run.command("submit")
@click.option("--queue", default="first-run-job-queue", help="Batch Queue")
@click.option("--jobname", default="1", help="Name of Job")
@click.option("--jobdef", default="test", help="Job Definition")
@click.option("--cmd", default=["uname"], help="Container Override Commands")
def submit(queue, jobname, jobdef, cmd):
"""Submit a job"""
result = submit_job(
job_name=jobname,
job_queue=queue,
job_definition=jobdef,
command=cmd
)
click.echo("CLI: Run Job Called")
return result
Lambda (EVENTS)
- Serverless
- Used in most if not all ML Platforms
- DeepLense
- Sagemaker
- S3 Events
Starting development with AWS Python Lambda development with Chalice
Demo on Sagemaker Terminal
https://github.com/aws/chalice
Hello World Example:
$ pip install chalice
$ chalice new-project helloworld && cd helloworld
$ cat app.py
from chalice import Chalice
app = Chalice(app_name="helloworld")
@app.route("/")
def index():
return {"hello": "world"}
$ chalice deploy
...
https://endpoint/dev
$ curl https://endpoint/api
{"hello": "world"}
References:
Serverless Web Scraping Project
[Demo] Deploying Hello World Lambda Function
Using Step functions with AWS
https://aws.amazon.com/step-functions/

Example Project:
https://github.com/noahgift/web_scraping_python
[Demo] Step Function
2.2 Data Cleaning and Preparation
Ensuring High Quality Data
- Validity
- Accuracy
- Completeness
- Consistency
- Uniformity
Dealing with missing values
Often easy way is to drop missing values
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/noahgift/real_estate_ml/master/data/Zip_Zhvi_SingleFamilyResidence.csv")
df.isnull().sum()
RegionID 1
RegionName 1
City 1
State 1
Metro 1140
CountyName 1
SizeRank 1
1996-04 4440
1996-05 4309
1996-06 4285
1996-07 4278
1996-08 4265
1996-09 4265
1996-10 4265
1996-11 4258
1996-12 4258
1997-01 4212
1997-02 3588
1997-03 3546
1997-04 3546
1997-05 3545
1997-06 3543
1997-07 3543
1997-08 3357
1997-09 3355
1997-10 3353
1997-11 3347
1997-12 3341
1998-01 3317
1998-02 3073
...
2015-04 13
2015-05 1
2015-06 1
2015-07 1
2015-08 1
2015-09 2
2015-10 3
2015-11 1
2015-12 1
2016-01 1
2016-02 19
2016-03 19
2016-04 19
2016-05 19
2016-06 1
2016-07 1
2016-08 1
2016-09 1
2016-10 1
2016-11 1
2016-12 51
2017-01 1
2017-02 1
2017-03 1
2017-04 1
2017-05 1
2017-06 1
2017-07 1
2017-08 1
2017-09 1
Length: 265, dtype: int64
df2 = df.dropna()
df2.isnull().sum()
RegionID 0
RegionName 0
City 0
State 0
Metro 0
CountyName 0
SizeRank 0
1996-04 0
1996-05 0
1996-06 0
1996-07 0
1996-08 0
1996-09 0
1996-10 0
1996-11 0
1996-12 0
1997-01 0
1997-02 0
1997-03 0
1997-04 0
1997-05 0
1997-06 0
1997-07 0
1997-08 0
1997-09 0
1997-10 0
1997-11 0
1997-12 0
1998-01 0
1998-02 0
..
2015-04 0
2015-05 0
2015-06 0
2015-07 0
2015-08 0
2015-09 0
2015-10 0
2015-11 0
2015-12 0
2016-01 0
2016-02 0
2016-03 0
2016-04 0
2016-05 0
2016-06 0
2016-07 0
2016-08 0
2016-09 0
2016-10 0
2016-11 0
2016-12 0
2017-01 0
2017-02 0
2017-03 0
2017-04 0
2017-05 0
2017-06 0
2017-07 0
2017-08 0
2017-09 0
Length: 265, dtype: int64
Cleaning Wikipedia Handle Example
"""
Example Route To Construct:
https://wikimedia.org/api/rest_v1/ +
metrics/pageviews/per-article/ +
en.wikipedia/all-access/user/ +
LeBron_James/daily/2015070100/2017070500 +
"""
import requests
import pandas as pd
import time
import wikipedia
BASE_URL =\
"https://wikimedia.org/api/rest_v1/metrics/pageviews/per-article/en.wikipedia/all-access/user"
def construct_url(handle, period, start, end):
"""Constructs a URL based on arguments
Should construct the following URL:
/LeBron_James/daily/2015070100/2017070500
"""
urls = [BASE_URL, handle, period, start, end]
constructed = str.join('/', urls)
return constructed
def query_wikipedia_pageviews(url):
res = requests.get(url)
return res.json()
def wikipedia_pageviews(handle, period, start, end):
"""Returns JSON"""
constructed_url = construct_url(handle, period, start,end)
pageviews = query_wikipedia_pageviews(url=constructed_url)
return pageviews
def wikipedia_2016(handle,sleep=0):
"""Retrieve pageviews for 2016"""
print("SLEEP: {sleep}".format(sleep=sleep))
time.sleep(sleep)
pageviews = wikipedia_pageviews(handle=handle,
period="daily", start="2016010100", end="2016123100")
if not 'items' in pageviews:
print("NO PAGEVIEWS: {handle}".format(handle=handle))
return None
return pageviews
def create_wikipedia_df(handles):
"""Creates a Dataframe of Pageviews"""
pageviews = []
timestamps = []
names = []
wikipedia_handles = []
for name, handle in handles.items():
pageviews_record = wikipedia_2016(handle)
if pageviews_record is None:
continue
for record in pageviews_record['items']:
pageviews.append(record['views'])
timestamps.append(record['timestamp'])
names.append(name)
wikipedia_handles.append(handle)
data = {
"names": names,
"wikipedia_handles": wikipedia_handles,
"pageviews": pageviews,
"timestamps": timestamps
}
df = pd.DataFrame(data)
return df
def create_wikipedia_handle(raw_handle):
"""Takes a raw handle and converts it to a wikipedia handle"""
wikipedia_handle = raw_handle.replace(" ", "_")
return wikipedia_handle
def create_wikipedia_nba_handle(name):
"""Appends basketball to link"""
url = " ".join([name, "(basketball)"])
return url
def wikipedia_current_nba_roster():
"""Gets all links on wikipedia current roster page"""
links = {}
nba = wikipedia.page("List_of_current_NBA_team_rosters")
for link in nba.links:
links[link] = create_wikipedia_handle(link)
return links
def guess_wikipedia_nba_handle(data="data/nba_2017_br.csv"):
"""Attempt to get the correct wikipedia handle"""
links = wikipedia_current_nba_roster()
nba = pd.read_csv(data)
count = 0
verified = {}
guesses = {}
for player in nba["Player"].values:
if player in links:
print("Player: {player}, Link: {link} ".format(player=player,
link=links[player]))
print(count)
count += 1
verified[player] = links[player] #add wikipedia link
else:
print("NO MATCH: {player}".format(player=player))
guesses[player] = create_wikipedia_handle(player)
return verified, guesses
def validate_wikipedia_guesses(guesses):
"""Validate guessed wikipedia accounts"""
verified = {}
wrong = {}
for name, link in guesses.items():
try:
page = wikipedia.page(link)
except (wikipedia.DisambiguationError, wikipedia.PageError) as error:
#try basketball suffix
nba_handle = create_wikipedia_nba_handle(name)
try:
page = wikipedia.page(nba_handle)
print("Initial wikipedia URL Failed: {error}".format(error=error))
except (wikipedia.DisambiguationError, wikipedia.PageError) as error:
print("Second Match Failure: {error}".format(error=error))
wrong[name] = link
continue
if "NBA" in page.summary:
verified[name] = link
else:
print("NO GUESS MATCH: {name}".format(name=name))
wrong[name] = link
return verified, wrong
def clean_wikipedia_handles(data="data/nba_2017_br.csv"):
"""Clean Handles"""
verified, guesses = guess_wikipedia_nba_handle(data=data)
verified_cleaned, wrong = validate_wikipedia_guesses(guesses)
print("WRONG Matches: {wrong}".format(wrong=wrong))
handles = {**verified, **verified_cleaned}
return handles
def nba_wikipedia_dataframe(data="data/nba_2017_br.csv"):
handles = clean_wikipedia_handles(data=data)
df = create_wikipedia_df(handles)
return df
def create_wikipedia_csv(data="data/nba_2017_br.csv"):
df = nba_wikipedia_dataframe(data=data)
df.to_csv("data/wikipedia_nba.csv")
if __name__ == "__main__":
create_wikipedia_csv()
Related AWS Services
These services could all help prepare and clean data
- AWS Glue
- AWS Machine Learning
- AWS Kinesis
- AWS Lambda
- AWS Sagemaker
2.3 Data Storage Concepts
Database Overview

Using AWS DynamoDB
https://aws.amazon.com/dynamodb/
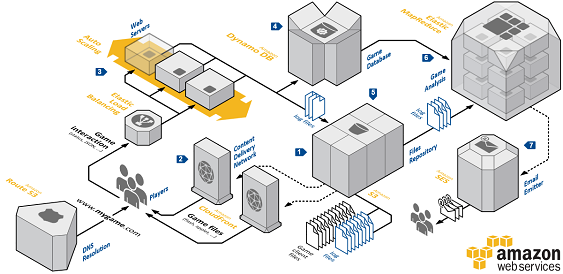
Query Example:
def query_police_department_record_by_guid(guid):
"""Gets one record in the PD table by guid
In [5]: rec = query_police_department_record_by_guid(
"7e607b82-9e18-49dc-a9d7-e9628a9147ad"
)
In [7]: rec
Out[7]:
{'PoliceDepartmentName': 'Hollister',
'UpdateTime': 'Fri Mar 2 12:43:43 2018',
'guid': '7e607b82-9e18-49dc-a9d7-e9628a9147ad'}
"""
db = dynamodb_resource()
extra_msg = {"region_name": REGION, "aws_service": "dynamodb",
"police_department_table":POLICE_DEPARTMENTS_TABLE,
"guid":guid}
log.info(f"Get PD record by GUID", extra=extra_msg)
pd_table = db.Table(POLICE_DEPARTMENTS_TABLE)
response = pd_table.get_item(
Key={
'guid': guid
}
)
return response['Item']
[Demo] DynamoDB
Redshift
- Data Warehouse Solution for AWS
- Column Data Store (Great at counting large data)
2.4 Learn ETL Solutions (Extract-Transform-Load)
AWS Glue
AWS Glue is fully managed ETL Service

AWS Glue Workflow
- Build Data Catalog
- Generate and Edit Transformations
- Schedule and Run Jobs
[DEMO] AWS Glue
EMR
- Can be used for large scale distributed data jobs
Athena
- Can replace many ETL
- Serverless
- Built on Presto w/ SQL Support
- Meant to query Data Lake
[DEMO] Athena
Data Pipeline
- create complex data processing workloads that are fault tolerant, repeatable, and highly available
[Demo] Data Pipeline
2.5 Batch vs Streaming Data
Impact on ML Pipeline
- More control of model training in batch (can decide when to retrain)
- Continuously retraining model could provide better prediction results or worse results
- Did input stream suddenly get more users or less users?
- Is there an A/B testing scenario?
Batch
- Data is batched at intervals
- Simplest approach to create predictions
- Many Services on AWS Capable of Batch Processing
- AWS Glue
- AWS Data Pipeline
- AWS Batch
- EMR
Streaming
- Continously polled or pushed
- More complex method of prediction
- Many Services on AWS Capable of Streaming
- Kinesis
- IoT
2.6 Data Security
AWS KMS (Key Management Service)
- Integrated with AWS Encryption SDK
- CloudTrail gives independent view of who accessed encrypted data
AWS Cloud Trail

- enables governance, compliance, operational auditing
- visibility into user and resource activity
- security analysis and troubleshooting
- security analysis and troubleshooting
[Demo] Cloud Trail
Other Aspects
- IAM Roles
- Security Groups
- VPC
2.7 Data Backup and Recovery
Most AWS Services Have Snapshot and Backup Capabilities
- RDS
- S3
- DynamoDB
S3 Backup and Recovery
- S3 Snapshots
- Amazon Glacier archive