Cloud Object Storage
Cloud Object Storage
At the heart of a Big Data is a Cloud Object storage system.
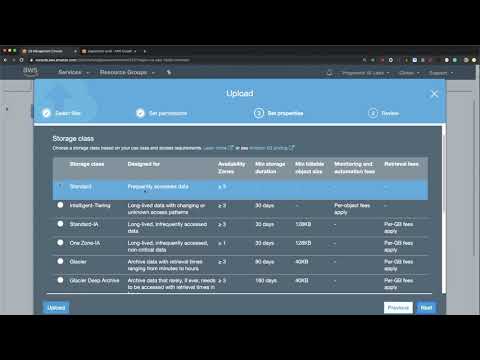
Amazon S3
The best known cloud object storage system is Amazon S3.
The Three “Vs” of Big Data: Variety, Velocity and Volume
There are many ways to define Big Data. One way of describing Big Data is it is data that it too large to process on your laptop. Another method is to the Three “Vs” of Big Data.

Variety
Many types of data.
- Unstructured text
- CSV files
- binary files
- big data files: Apache Parquet
- Database files
Velocity
Are data written at 10’s of thousands of records per second? Are there many streams of data written at once?
Volume
Is the actual size of the data larger than what a workstation can handle? Perhaps your laptop cannot load a CSV file into the Python pandas package. This could be Big Data. One Petabyte is Big Data and 100 GB could be big data depending on the system processing it.
Batch vs Streaming Data and Machine Learning
Impact on ML Pipeline
- More control of model training in batch (can decide when to retrain)
- Continuously retraining model could provide better prediction results or worse results
- Did input stream suddenly get more users or less users?
- Is there an A/B testing scenario?
Batch
- Data is batched at intervals
- Simplest approach to create predictions
- Many Services on AWS Capable of Batch Processing
- AWS Glue
- AWS Data Pipeline
- AWS Batch
- EMR
Streaming
- Continuously polled or pushed
- More complex method of prediction
- Many Services on AWS Capable of Streaming
- Kinesis
- IoT